A data scientist is just a software engineer

This might be a provocative title for both data scientists and software engineers. An experienced backend developer might assert that an engineer is much better at writing production code. A data scientist will claim that the exploratory nature of work in the ideation stage of new products and features (especially data-driven ones) is more suitable for them.
The point, of course, is not that the roles are identical. It is rather that for the purposes of setting up processes and organisation, it might make sense to treat these roles similarly, rather than e.g. treat a data scientist like a data analyst. This more correct classification will facilitate managing data science projects, setting expectations and delivering value.
Archetypes
There are a few alternative ways to view data scientists in an organisation:
| Archetype | Produces | Realistic? |
|---|---|---|
| Wizard | Magic | No |
| Researcher | Research | No |
| Analyst | Knowledge | Yes |
| Engineer | Software | Yes |
The Wizard
This is the first model that is usually intrinsic for organisations of low technological maturity or small startups. The Wizard joins in a vaccuum of processes or organisational support, but with immense expectations on them, as the responsible stakeholder has heard of cool AI applications implemented at Google.
Over time, it is inevitable that the expectations and the way stakeholders view the data science role shift away from this archetype. In practice, the scientist here often finds there is actually not much modelling and advanced analytics to do, and the nature of the work boils down to basic business intelligence. Much like in the Maslow’s Hierarchy of Needs breathing is more important than self-esteem, in an organisation having a rudimentary dashboard for revenue is more important than implementing a neural network (probably on broken data).
The Researcher
For some reason, this archetype is the one that many (junior) data scientists themselves build their expectations on. They think their day to day work will revolve around building novel publication worthy methodologies, such as custom architectures in PyTorch. In reality, this Research will form a small part of their work (at least for most roles called data scientist/machine learning engineer). Most likely, this expectation mismatch is driven by the momentum of academia, which rewards novelty over impact, in clear opposition to industry.
The Analyst
A data analyst is a necessary workhorse in a technology company. They typically keep a finger on the business pulse, supporting decision making with visualisation tools, automated reports, ad hoc analyses, domain knowledge and more. Many data analysts I know have similar skills to data scientists: they are not unfamiliar with machine learning models and statistical methods. The main difference drives from expectations for the roles: an Analyst’s output is what we can call knowledge, while a data scientist mainly produces software (more on this below).
The Engineer
A software engineer’s role is relatively better established thanks to its longer history. In general, less expectations are set on the Engineer compared to the Wizard, as good managers understand big changes are the result of incremental progress of strong teams, rather than sporadic contributions of ingenious Wizards. The Engineer is expected to research the best practice methodologies, tools and papers for new projects. In practice, the 80/20 tradeoff often implies using some existing library for complex logic, rather than implementing a functionality from scratch. Finally, a good Software Engineer still does data analytics, especially in the ideation phase of new designs, but the main difference to a Data Analyst is the nature of deliverables - software, not knowledge.
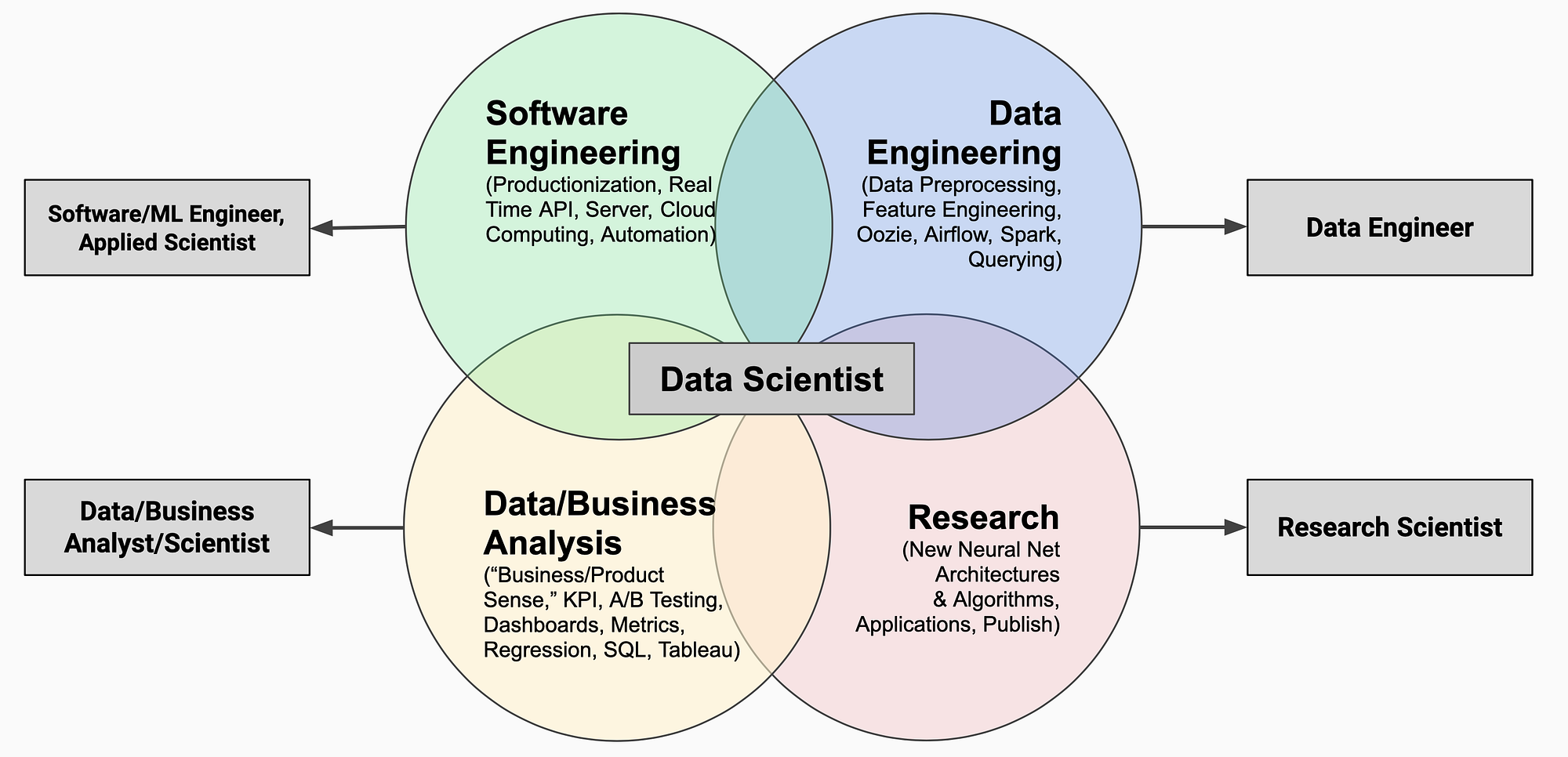
Here’s another similar breakdown of data science subskills from an article by Jason Jung. However, if I had to assign linear weights to these that were proportional to the time spent in different work modes (based on the data scientists/ML engineers I know), I’d say it’s something like:
- 0.3 software engineering
- 0.4 data engineering
- 0.25 data analysis
- 0.05 research
I consider data engineering a subset of software engineering, thus 70% of time is spent on doing work related to software engineering.
Scientist vs Engineer
Let’s review the differences and similarities between data science and software development, to see if the roles are similar enough to be useful.
Differences
One of the main differences is in planning and executing projects. Classical software projects are usually binary in the sense that they have less uncertainty about the expected implementation and its accuracy. There are product requirements, which are translated into a technical specification, which is then implemented in code. Note that most software engineering design docs are written before the implementation.
Data science projects have inherently high uncertainty . You never know the accuracy of a model until you implement a prototype. Moreover, the model is never “done” as a typical software project might be. A new hotshot scientist might come in 2 weeks later with a clever idea for feature engineering that significantly improves the model’s accuracy, enabling new product features that weren’t even imagined before. At Bolt, data science design docs are invariably written after implementation, and have often transformed significantly compared to the initial idea.
This phenomenon means that data scientists work much more often with disposable notebooks and scripts to validate quick hypotheses - probably where the notion that they can’t write proper code comes from. In the terminology of Pragmatic Programmer, data scientists most often work with Prototypes - a necessity for experimental features.
Similarities
The main similarity - and distinction from the Data Analyst archetype - is that data scientists are expected to deliver software, rather than just reports, dashboards, opinions or informative graphs. This usually takes the form of microservices hosting model artifacts that can be used for inference by backend callers.
Once you’ve deployed the model, it becomes a continuous item of maintenance, as there is a need for:
- Monitoring and logging
- Managing technical debt
- Adding new features in a backwards compatible way, taking into account existing users
In other words, a producer of software also assumes ownership of it.
Finally, both data scientists and software engineers are evaluated for some generic skills, which are again related to producing software:
- Translating business problems into technical specifications
- Handling dependencies with other teams
- Taking a customer oriented view in design
- Taking into account diminishing returns during prioritising and planning
- Evaluating new technologies and methods for doing things in a better way
What it implies for your data science team
As data scientists produce code that will be used in production, it needs to be of high quality. To ensure this, we can reuse many of the processes and tools from software engineering developed over the past few decades, such as:
- Using code versioning systems
- Working in pull request, enforcing reviews
- Using linters, debuggers, profiling
- Automating deployment through CI/CD tools
- Writing tests for the entire model pipeline. Machine learning models generally require more complex tests than usual software, as you want to ensure the (black-box) model behaves well in corner cases, adheres to your assumptions, your validation framework simulates the production environment, there is no data drift in production etc.
Another takeaway, mostly for managers, is about how to set processes and expectations for data science teams. As Wizard and Researcher are unrealistic archetypes, it usually boils down to a choice between Engineer and Analyst (you can also consider it a spectrum). It seems to me that the optimum is closer to Engineer.
It is generally not a good idea to work on high uncertainty research items without clearly defined outcomes (“Just look at this data and see if you can come up with any good ideas”) and deliverables - on an interesting enough problem, you could easily spend years! Instead, we can adopt some useful planning methods that are used for complex software projects:
- Clearly defined target metrics
- Always going for the 80/20 MVP instead of the ideal solution
- Timeboxing uncertain projects into clearly defined deliverables (finish data querying in week 1, implement preprocessing in week 2, train a simple logistic regression in week 3, fine-tune a state of the art neural network in week 4)
- Shifting the planned deliverables from interesting knowledge to automated actions (software). One of the first questions I ask when someone proposes to look into some interesting data is - “how do you think we can improve the product using this data, and do this in an automated and scalable way?”
NB: Should you then copy all software engineering processes and apply them to your team? Probably not! Weekly sprint sessions? Daily standups? Ugh! The differences section above is a good reason why to not do that. Instead, my argument is that there are a few useful tricks we can lend from the field of software engineering.