Perceptually lossless (talking head) video compression at 22kbit/s
Update: Discussion on Hacker News
I’ve been having quite a bit of fun with the fairly recent LivePortrait model, generating deepfakes of my friends for some cheap laughs.

The inevitable Elon Musk deepfake, picture by Debbie Rowe
The emerging field of 2D avatar/portrait animation (being able to animate any still image, avoiding the need to render cumbersome 3D models that would struggle with small facial details) is a harbinger of things to come. In the best case, it will be ubiquitous on social media (the authors have already added an extension to animate cute animal faces) and in the worst, trust on the internet will be heavily undermined. But one overlooked use case of the technology is (talking head) video compression. After all, prediction is compression, so a sufficiently powerful face generator should be able to compress frame information into an extremely sparse set of cues to reconstruct the same frame from.
This was briefly explored in Nvidia’s seminal facevid2vid paper that compared their models’ compression ratio to the classical H.264 codec. The main idea is quite simple: given a source image that is shared between the sending and receiving side, the only information that needs to be transmitted is the change in expression, pose and facial keypoints. The receiving side then simply animates the source frame into the new one, using these motion parameters.

The main upside is that this method achieves pretty reasonable perceptual quality at an extremely low bitrate, while at a comparable level a traditional video codec will show heavy artifacts. There are, of course, downsides as well:
- there is no longer a natural lever to trade-off between quality and bitrate, like the CRF for H.264.
- as a model with large generative capacity, there’s essentially no limit to how bad the worst case reconstruction can be. It could in theory render a completely different person, or distort your face into a monstrous gremlin.
- the impressive bitrate does not come for free, as e.g. LivePortrait needs to run on an RTX 4090 for real-time processing. In the space of possible learned compression models, compared to something like DCVC, it is a further improvement in compression rate, at the cost of having a 10x+ slower model.
Anyway, LivePortrait is a beefed up version of facevid2vid, so let’s look at how good it is for video compression. I extracted the first frame of the above driving video as a key frame, simulating a scenario where instead of a high quality enrolled image, key frames are extracted on-demand in the background. This means that in addition to being same identity animation, this is also same video animation - by far the simplest scenario to work on for the model, as you have very good alignment between the source and driving frames. It’s also the closest to a drop-in replacement of the current video call experience. Here are the results of a quick try:
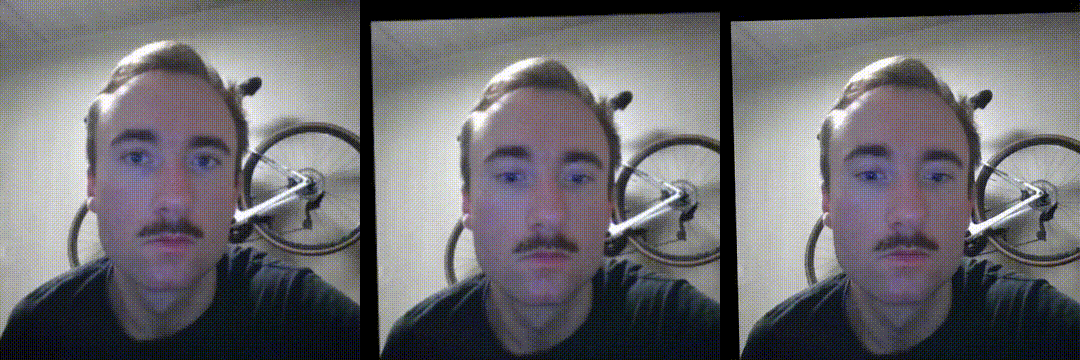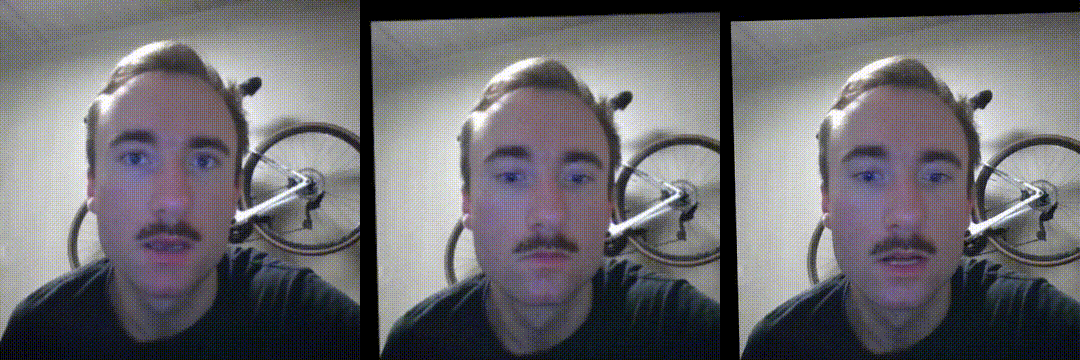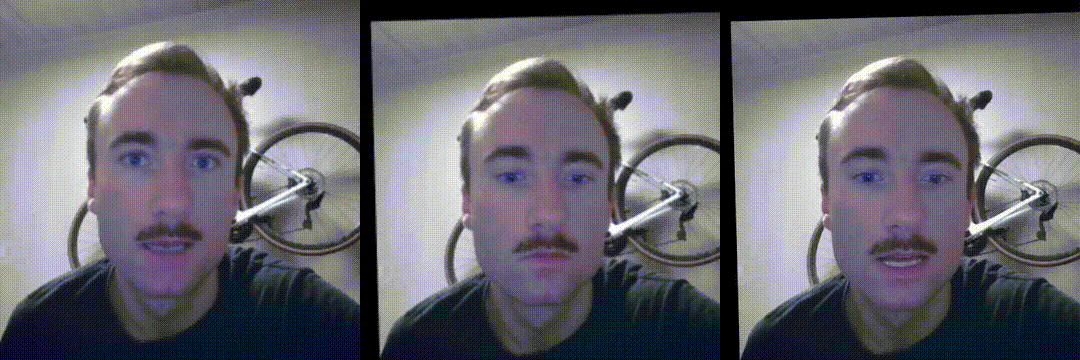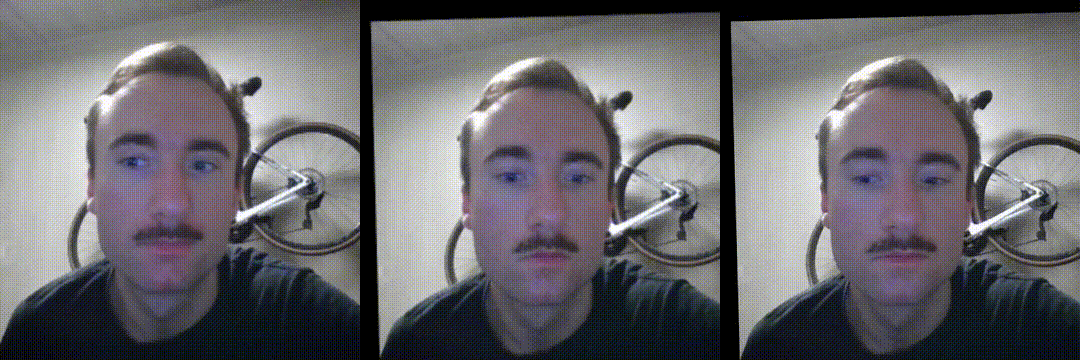
Self-animation, i.e. driving a keyframe of the video with the motion
It’s possible to uncover discrepancies in a side by side analysis:
- the head tends to be a bit shaky in all my experiments, probably because LivePortrait processes frames in isolation, without any motion prior. Or maybe my driving video is low quality. 🤷
- since the eye gaze is off camera in the key frame (“neutral mode”), the model seems to map it incorrectly in every frame after that.
- teeth are generally hallucinated, but this is only noticeable in smiling videos.
As expected, the discrepancies are much more obvious if we provide a driving video with shoulder movement and difficult head angles. Also, the further the inference setup is from the training one (which is same video animation), the worse the results.
Nonetheless, it’s clear that there is a set of frames, arguably a large proportion of video-conferencing, where the model manages to produce subjectivelly distinguishable reconstructions. Sure, in a side by side analysis we might be able to tell which is the original and which is the reconstruction. However, if you are only looking at the generated output, it works very well.
So how small is the bitrate of this reconstruction? The model equation for transforming the face keypoints is:
\[x_d = s_d \times (x_{c, s} R_d + \delta_d) + t_d\]where $x_{c, s} \in \mathbb{R}^{K \times 3}$ are the “canonical” implicit 3D facial keypoints of the source image, $R_d \in \mathbb{R}^{3 \times 3}$ is a 3D rotation matrix (relative to the canonical keypoints), $\delta_d \in \mathbb{R}^{K \times 3}$ denotes the expression deformations, $t_d \in \mathbb{R}^3$ is a translation vector and $s_d$ is just a scaling coefficient and $K$, the number of keypoints, is a hyperparameter. The intuition of this equation is provided in the Nvidia paper:
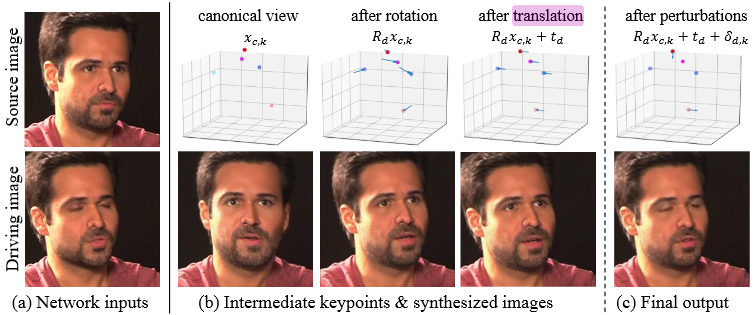
Of course, $x_d$ is not yet the final reconstruction of the image, only the transformed keypoints. There are some flow field estimations and warp operations remaining to actually turn the source image into the driving one. Nonetheless, the sender only needs to transmit $s_d$, $R_d$, $\delta_d$ and $t_d$ for a lifelike reconstruction to happen on the receiver’s side.
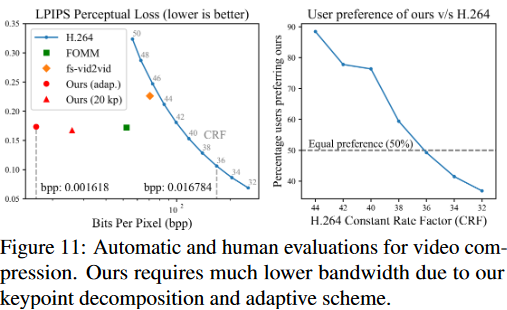
And since we know their shapes, we can also infer the bitrate: $3 \times 3 + K \times 3 + 3 = 75 $ numbers at $ K = 21 $, the default LivePortrait setting. At half precision floats, that’s $ 16 \times 75 \times 30 $ bits per second for a 30FPS video, or 36kbit/s. This could be compressed further - note that each frame is processed in isolation. This could be alleviated with entropy coding and having a temporal prior. In facevid2vid, simple entropy coding reduced the baseline model’s bitrate by nearly 40%, while using an adaptive number of keypoints reduced it by 60%. Using the first figure, we should be able to bring down LivePortrait’s bitrate to about 22kbit/s. For reference, the low bitrate challenge in CLIC 2024 featured video compression at 50kbit/s, but as expected, the models showed significantly worse subjective quality scores than at 500kbit/s.
LivePortrait has roughly the same bitrate as the facevid2vid had (model transmits similar information), but achieving better results. Looking at the evaluation results for the latter method, we see that as expected, their model only provides a single point on the bitrate-quality curve. So without any evaluation results at hand, I would expect LivePortrait to move strictly downwards, matching a lower H.264 CRF for equal preference. Extrapolating ahead, a future model might achieve the same perceptual quality as a visually lossless CRF (FFmpeg suggests 17 or 18). Then, it is up to the user whether they want to squeeze bitrate to near zero at the cost of compute.
How does it work (what is the magic?)
The main problem of frame animation is that we are projecting a 3D object to a 2D image. So our model needs to understand the rotation and deformation of the underlying object. The good thing about faces is that they are rigid, i.e. tends to have limited degrees of freedom in movement and nearby pixels move together in predictable ways. Nonetheless, this has proven to be a hard problem.
The main innovation of facevid2vid, that also powers LivePortrait, was realising that this can be formed as a 3D rotation problem. By rotating a set of abstract 3D tensors enough times, the model learns to actually map these to keypoints of the face, as if someone would have painstakingly labelled them for each frame. Up until then, models like First Order Motion Model had also used the implicit keypoints approach, but only with 2D keypoints.
The second thing that seems to work is quite humdrum: compared to facevid2vid, LivePortrait has seriously scaled up the training dataset to 69 million high quality frames, and added regional GAN losses that focus only on the local regions like the face or the lips. So rather than any architectural breakthrough, it seems to have been a lot of iterative improvements on dataset and losses.
While being able to learn facial keypoints self-supervisedly is a testament to why deep learning is cool, it also allows direct controllability of the avatar. Since the rotation matrix has a direct geometric interpretation, you can input parameters for a required pose. LivePortrait adds on top of this by training small neural networks to control lip and eye movement. This is a big step ahead in terms of avatar controllability which generally has not been a strong suit of many generative approaches (I’m looking at you, diffusion).
LivePortrait methodology is quite different from SotA learned video compression models like DCVC, which need to encode spatial information with a great degree of fidelity targeting pixel-aligned distortion losses such as MSE. A generative model unencumbered by pixel-alignment and optimised for various GAN based perceptive losses, only tries to generate something plausible. On a spectrum of model architectures, it achieves higher compression efficiency at the cost of model complexity. Indeed, the full LivePortrait model has 130m parameters compared to DCVC’s 20 million. While that’s tiny compared to LLMs, it currently requires an Nvidia RTX 4090 to run it in real time (in addition to parameters, a large culprit is using expensive warping operations). That means deploying to edge runtimes such as Apple Neural Engine is still quite a ways ahead.
Nonetheless, models and hardware become faster reliably quickly. Also, the same identity animation problem is significantly easier than animating Elon Musk or your cat, so probably a model optimised for teleconferencing could be remarkably smaller. That’s why it might not be that much of a moonshot. Publicly, Zoom seems to have played with the idea of avatar technology. I’ll let the precise use cases be determined by product people, but off the top of my head:
- having a more formal version of yourself avatar for days when youre working in your underwear
- animating a 4k studio quality avatar from a driving video from my terrible webcam
- using pose and gaze connection to seat the avatars in some kind of more immersive virtual meeting room
- letting your avatar attend meetings / send messages as a digital twin. If all the driving keypoints are directly manipulatable, you could programmatically control a photorealistic video.
Of course it’s possible that none of these will be useful or socially normalised, yet its fun to theorise.