ML research and startups
Machine learning is a field heavily tied to science. Even when normalising on years of experience, the share of engineers with a PhD and prior publications is much larger in ML compared to overall engineering. This naturally creates an affinity to academic research and working on complicated problems that require complex (not off the shelf) solutions. Many of today’s data scientists and ML engineers would like to upskill towards research, but what to actually expect from industry work?
Research is an ambiguous term in industry, so for the following let’s define it as both:
- Research science - actively publishing novel research for expanding the knowledge frontier, working with ideas and prototypes
- Research engineering - implementing and optimising solutions near the knowledge frontier, working with production grade systems
It seems that the first one is almost exclusively dominated by big tech companies:
There are other slightly smaller companies that can still produce NeurIPS level research like Spotify or Uber, but the smaller the market cap of the company, the less likely it is that their research scientists are working full time near the knowledge frontier.
Why is this?
Publication is a non-direct benefit to the employer. There is no obvious revenue/profit contribution from publishing at a top journal or conference. There are many indirect benefits, such as attracting top talent, better brand recognition and driving innovation. However, fledgling startups have 99 problems and these kind of soft benefits tend to not make it into the priority shortlist. This means that if you are dreaming of working on cutting edge solutions and have publishing be part of your expected work, then big tech might be the only feasible place. Somewhere between 50-100B market cap seems to me to be the starting point where you could expect research scientist to be an actual open role.
So that leaves us with research engineering. Surely one can do this at a small company, right?
Some project lifecycle curves
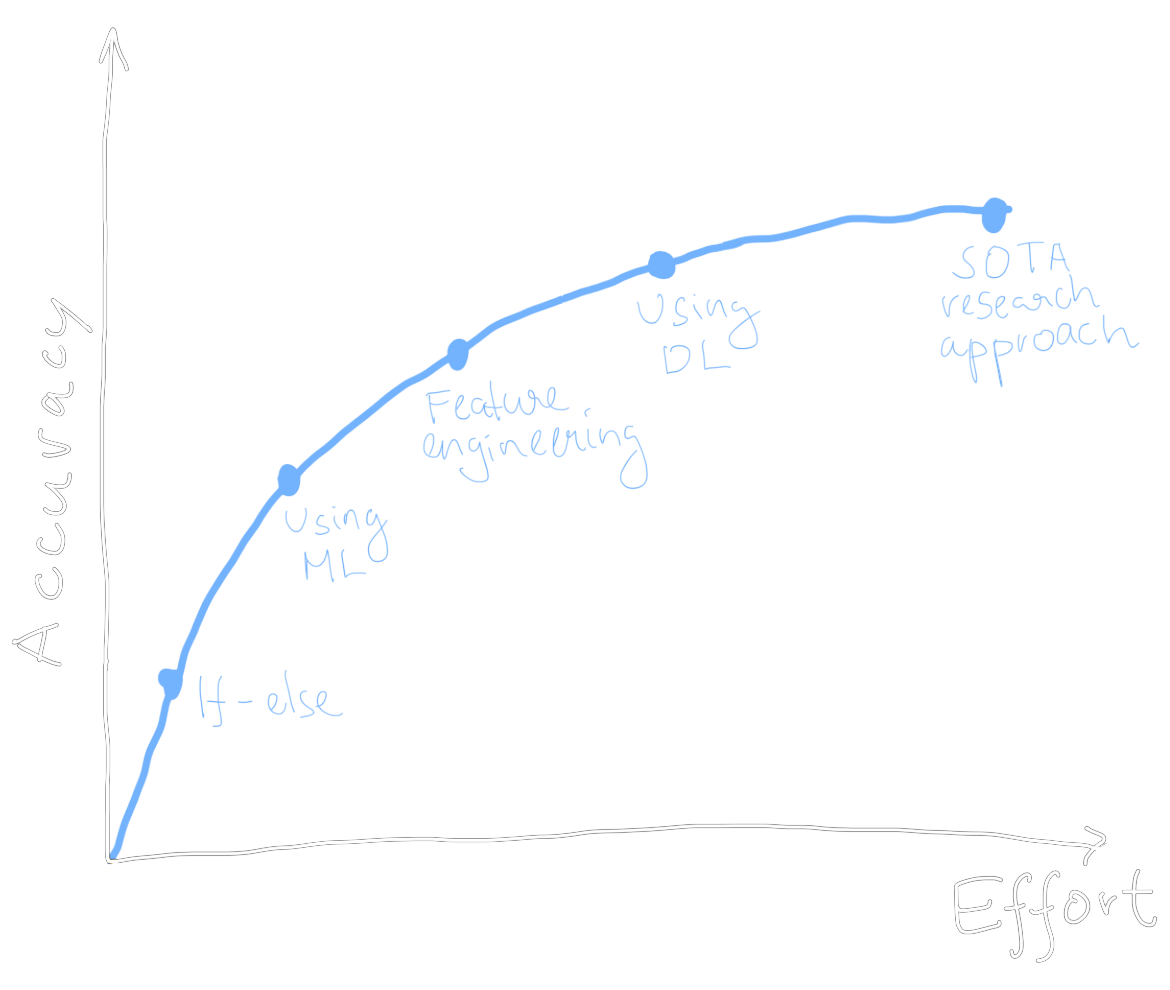
The average lifecycle of an ML project looks something like the above (where ML denotes machine learning and DL deep learning). In practice, you may use versioning lingo such as “V1” and “V2” for the different stages of a model. There is only one important thing to note about the function: it is concave ($ f’(x) > 0, f^{(2)}(x) < 0, \forall x$). In other words, there are diminishing returns from investing more effort into the approach. For any given model solving some task, we expect to improve it more rapidly during the initial “low hanging fruit” stage, compared to when someone has already spent 3 years working on it.
Imagine a rapid grocery delivery startup who’s hired a team of ambitious data scientists to solve various machine learning problems at the company. Let’s say there are 5 main opportunities that have been identified by management:
- Dynamic pricing to balance demand/supply (e.g. increase courier fees during peak hours)
- Improving the dispatching engine (ML arrival time predictions + optimal order batching)
- Computer vision for automated courier/restaurant on-boarding
- Personalised recommendations in the user app
- Using Gen AI to produce synthetic menu images
To simulate this scenario, we can generate a number of effort-accuracy curves from any concave function, for below I use $ f(x) = a \log(bx)$.
As I’ve argued before, companies solve an optimisation problem to maximise returns given some fixed effort budget. The only remaining problem is that on our y-axis we currently have accuracy, not (monetary) returns. The company optimises wrt to $ \frac{\partial Returns}{\partial Effort} = \frac{\partial Returns}{\partial Accuracy} \frac{\partial Accuracy}{\partial Effort} $. However, let’s assume without loss of generality that $ \frac{\partial Returns}{\partial Accuracy} $ is linear and has the same coefficient for each project - then the optimisation problem boils down to maximising the sum of accuracies. It seems likely that if anything, $ \frac{\partial Returns}{\partial Accuracy} $ is itself concave (going from 50->60 pp accuracy is perhaps more business-enabling than going from 90->100), so $ \frac{\partial Returns}{\partial Effort} $ would be even more concave, but linearity doesn’t change the nature of the problem either.
If the projects are independent, the optimal allocation can be approximated with the following algorithm:
effort_per_project = defaultdict(lambda: 0)
total_effort = 100
for _ in range(total_effort):
# Take the analytical or empirical derivative
marginal_gains = [derivative(effort_curve(current_effort)) for effort_curve, current_effort in zip(effort_curves, current_efforts)]
# Allocate 1 unit of effort to project with highest gain
project_to_allocate = np.argmax(marginal_gains)
effort_per_project[project_to_allocate] += 1
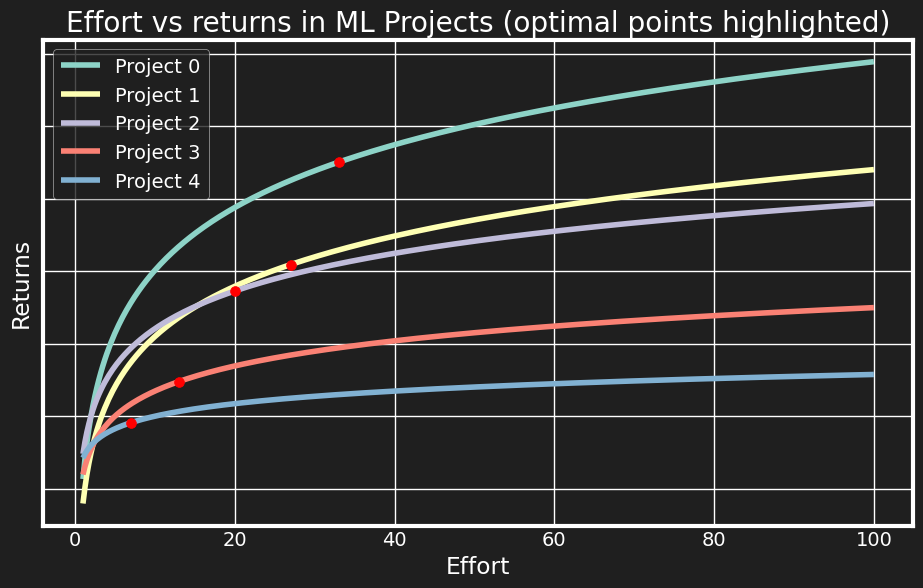
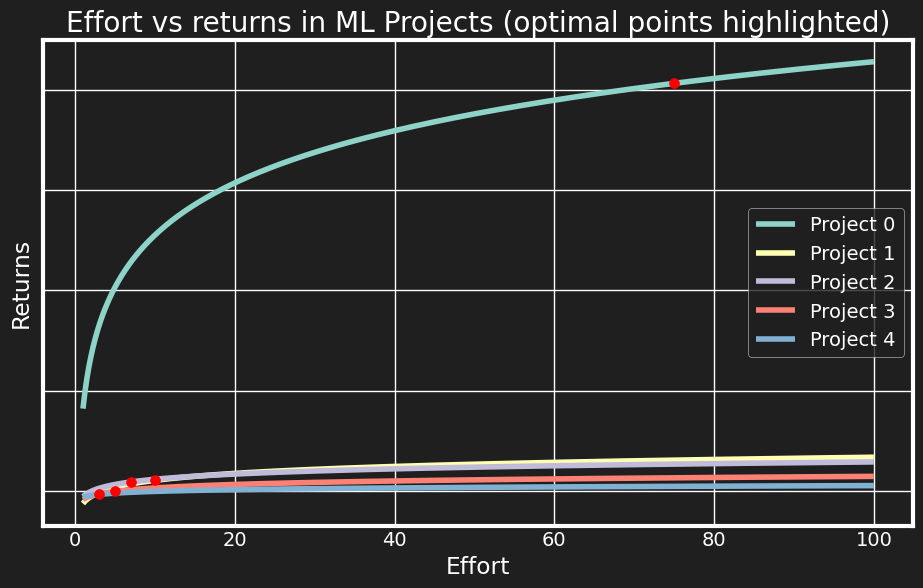
Above, the optimal allocation for each project is shown in red dots, and it is clear that when facing diminishing returns, it is not rational to invest too heavily in any one project. However, the juxtaposition with the first image shows that this means not investing further than some basic feature engineering improvements! We shouldn’t even start looking into deep learning architectures, let alone the research frontier implementations.
This visualises the fundamental tradeoff between industry priorities (impact) and academic priorities (novelty). Even if the
data scientists would prefer to work on the top importance project and bring it into the SotA territory - and with a budget of 100 total_effort, this would be feasible - they are not able
to, because there are various different projects that require keeping their lights on.
There are two possible necessary conditions to get to the “SotA research approach” area of the curve for any given project.
Firstly, let’s look at the same optimisation solution, but this time expand total_effort to 300. Intuitively, this corresponds to
the growth of the company - the most valuable ML projects remain more or less the same, but due to improved resources,
we can invest more. An alternative way to look at this is increasing effort surplus causing further specialisation. This is similar to how
human societies have evolved - at first, almost everyone was a farmer, but as food surpluses accumulated, you could have
marketers, social media specialists and prompt engineers as well. 🙂
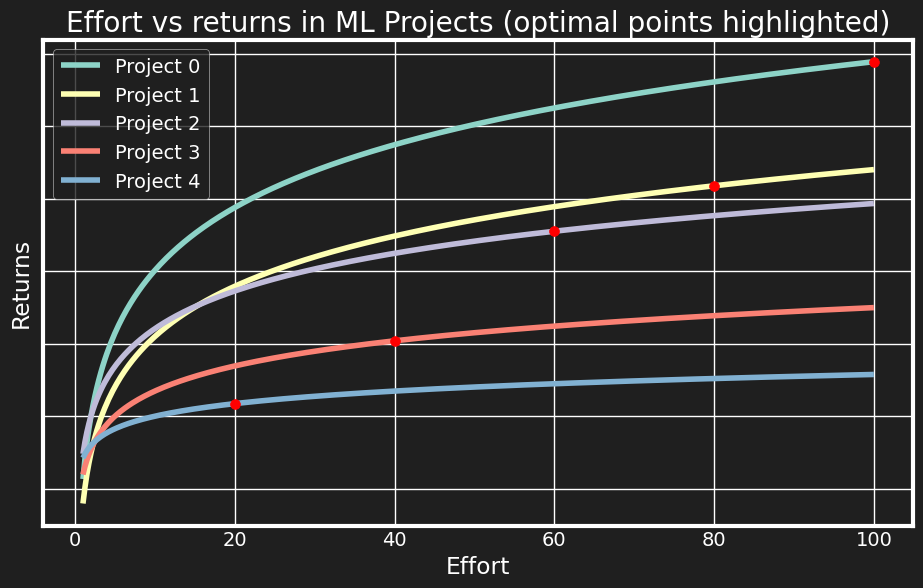
We see now that it is optimal for the company to invest into research frontier level improvements to the first project. So if you work at Google, your solution for the quarterly fraud detection model task might be novel enough to warrant publishing in KDD.
The second way to have an optimal allocation nearing the SotA region for the top project is to change the relative importance of projects. In real life, different companies have a different distribution of ML priorities. Some, which I denote as “ML-first” product companies, have their core product success hinging on some ML model. Take, for example, Starship Technologies, developing cute autonomous sidewalk robots. They needed to build up a perception team relatively early, because without perception, you have no autonomy, and thus no product. Other possible ML use cases, such as travel time prediction, fraud prevention or customer segmentation, came much later. Similarly, if you’re selling an OCR service, or a foundational LLM, the core business success is intimately tied to the ML solution. We can represent this graphically by making one of the projects much more prominent:
The final takeaway is simple: if you want to publish, you will be mostly disappointed at a startup. If you want to work on cutting edge engineering, then a startup will work if their product is ML-first. Be sure to ask in interviews how critical is the ML solution to the company, if it falls into the nice-to-have category, it’ll likely not have a SotA solution. Otherwise, the amount of interesting ML engineering work scales with the size of the company.